Cos’è un Data Lake?
el 09 de Giugno de 2017
el 09/06/2017
Probabilmente avrai già sentito questo termine occasionalmente e ti sarai chiesto “cos’è un Data Lake?” Anche se la tua azienda non è matura lato Business Intelligence, sicuramente non hai ti sarà ancora capitato di subire i problemi che questa situazione causa. E, di conseguenza, non hai avuto motivo di avvicinarti al concetto di Data Lake.
Come puoi immaginare, uno dei maggiori problemi con cui si confronta un’azienda è l’aumento della mole di dati. Nell’era digitale, in cui siamo immersi nei dati, le informazioni sono ovunque. E si moltiplicano alla velocità della luce.
E tutti i dati possono avere un valore. In altre parole: devi considerarli. Ed è qui che entra in gioco l’organizzazione e la gestione per organizzare queste conoscenze.
INDICE DEI CONTENUTI
Vuoi sapere cos’è un Data Lake?
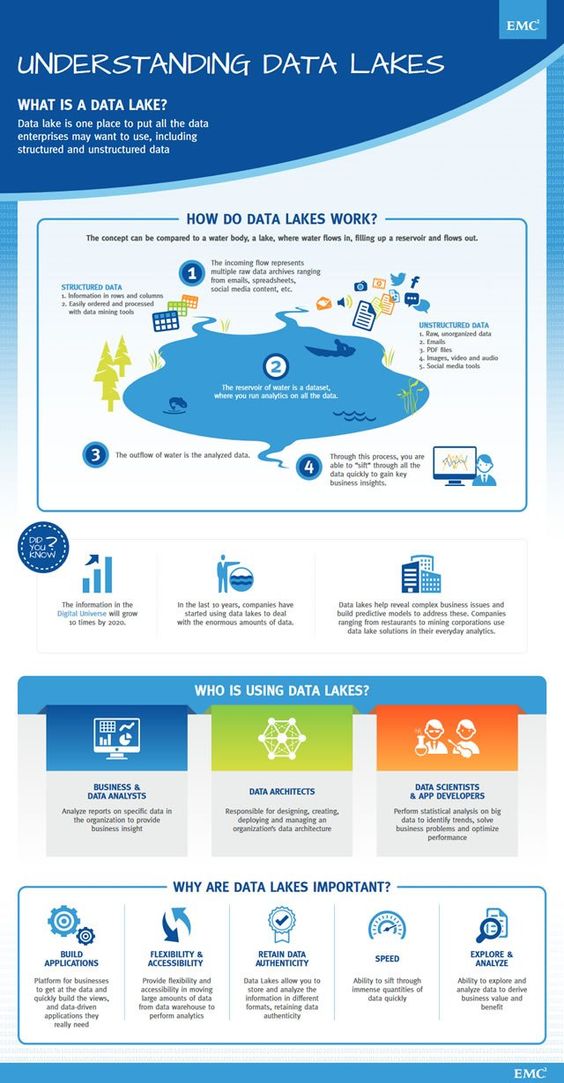
Probabilmente avrai messo in relazione questo concetto con il Big Data. Un Data Lake è una repository in cui si immagazzinano tutti i dati aziendali. Indipendentemente dal fatto che siano strutturati o no, sono tutti grezzi, senza organizzazione, per essere analizzati successivamente.
Le aziende recuperano i dati quando vogliono. Solo in questo momento si procede ad organizzarli e a creare una struttura che renda più facile l’analisi.
Il Big Data, invece, entra in gioco in questa seconda fase. Dato che si riferisce alla struttura in cui i dati vengono stoccati. Perché tu lo capisca, una volta cominciata l’analisi delle informazioni possono essere effettuate tre azioni:
- Creare una politica pubblica.
- Creare una strategia di marketing.
- Prevedere l’evoluzione di una malattia nella popolazione.
Come si può fare? Immedesimati nella situazione. Se hai un report medico dei pazienti di un centro, sarà più facile trovare un modello di contagio relativo ad una malattia.
Ti chiedi se ha a che fare con il marketing? Se un negozio di abbigliamento, per esempio, rileva le preferenze dei suoi clienti, saprà quali sono i loro prodotti preferiti o quando prevedere vendite ridotte. Sarà quindi più facile determinare i momenti chiave per lanciare promozioni.
Che differenze ci sono tra un Data Lake e un Data Warehouse?

Fare una comparazione tra un Data Lake e un Data Warehouse è uno dei modi migliori per comprendere come si stanno evolvendo i sistemi di immagazzinamento dei dati. Come puoi vedere nell’infografica di DataFlog, ogni sistema ha i suoi pro e i suoi contro.
1.- Un Data Lake conserva tutti i dati
Durante lo sviluppo di un archivio dati si consuma una quantità considerevole di tempo per analizzare le fonti, verificare i processi e profilare i dati. Come risultato, si ottiene un modello di dati altamente strutturato e pronto per la generazione di report.
Gran parte di questo processo include una fase di decisioni da prendere. Quali dati devono essere inclusi e quali no. In generale, se i dati non vengono utilizzati per rispondere a domande specifiche o non sono imprescindibili nei report, possono essere esclusi. In questo modo si semplifica il modello e si conserva lo spazio.
Ovviamente, un Data Lake conserva tutti i dati. Non solo quelli vitali ma tutti quelli che sono salvati e che possono essere eventualmente necessari. Aspetto che genera benefici soprattutto durante la fase di analisi.
Ciò è possibile perché l’hardware di un Data Lake è diverso da quello che si utilizza per l’immagazzinamento dei dati generali. La comodità, i server disponibili e l’immagazzinamento conveniente permettono un ampliamento di un Data Lake a terabytes e petabytes abbastanza economico.
2.- Un Data Lake supporta ogni tipo di dato
Gli archivi di dati generalmente consistono in informazioni estratte da sistemi transazionali. E quindi, includono metriche quantitative e altri attributi che li descrivono.
Le fonti dei dati non tradizionali come possono essere i dati sensibili, l’attività di un determinato social, immagini o testi di solito si ignorano. E anche se possono essere riutilizzati, lo stoccaggio ha un costo elevato ed è abbastanza complicato.
Per farti capire bene cos’è un Data Lake considera che questo concetto riguarda tutti i dati non tradizionali. Ossia, si archivia tutto senza considerare la struttura o la fonte. Si mantiene l’informazione grezza e si trasforma solo nel momento in cui essa è necessaria.
Questo approccio si conosce come “Schema on Read” rispetto all’approccio “Schema on Write“utilizzato nel Data Warehouse.
3.- Il Data Lake supporta tutti i tipi di utente
Nella maggior parte delle organizzazioni, oltre l’80% degli utenti sono funzionali. Ossia, vogliono ottenere report, vedere metriche chiave di rendimento o lavorare sui medesimi dati quotidianamente. Per loro, il Data Warehouse è ideale. Offre una struttura chiara, facile da usare, da comprendere e, soprattutto, è creato per rispondere alle domande.
Un 10%, invece, fa analisi diverse su questi dati. Ossia, questi utenti utilizzano il Data Warehouse come una fonte aggiuntiva. Ovviamente, spesso tornano ai sistemi originari per ottenere dati che non sono inclusi nell’archivio. E inseriscono nuovi dati provenienti dall’esterno.
Infine, il 10% rimanente effettua analisi profonde. Questi utenti sanno cos’è un Data Lake e creano fonti di dati totalmente nuove basate sull’investigazione. Studiano molti tipi di dati fino a generare nuove domande e risposte alle loro necessità
Anche se possono usare il Data Warehouse preferiscono ignorarlo. Il suo utilizzo presuppone una conoscenza di cui non dispongono. Tuttavia, hanno una scienza dei dati e utilizzano strumenti analitici avanzati.
L’obiettivo del Data Lake è appoggiare tutti gli utenti allo stesso modo. La scienza dei dati legata al Data Lake lavora con le informazioni grezze. Invece gli altri utenti utilizzeranno viste più strutturate dei dati forniti appositamente per questa necessità.
4.- I Data Lakes si adattano facilmente ai cambiamenti
Uno dei principali svantaggi dei Data Warehouse è che non si adattano ai cambiamenti. Considera che durante lo sviluppo della struttura di archivio si spende un tempo considerevole, nonostante una buona architettura del “magazzino” sia in grado di adattarsi alle modifiche, il processo di caricamento dei dati è così complesso che questi cambiamenti utilizzeranno alcune risorse degli sviluppatori, occupando tempo.
Come puoi immaginare ci sono diverse richieste commerciali da gestire. E non possono attendere l’adattamento dell’archivio. Attualmente l’utente vuole risposte immediate. E per lo stesso motivo sono stati creati molti sistemi di auto servizio di intelligenza imprenditoriale. Sistemi che rispondono automaticamente per guadagnare tempo ed essere più efficaci.
Per comprendere cos’è un Data Lake, devi avere chiaro un aspetto: sono gli utenti che hanno il potere di andare oltre la struttura di archivio. Considerando che tutti i dati vengono immagazzinati in forma grezza e sono sempre disponibili, queste azioni diventano possibili.
Si dimostra che il risultato di questa esplorazione è utile e può essere ripetuta e applicata ad uno schema formale. È qui che si potrebbero sviluppare sistemi di automatizzazione e riutilizzo per estendere i risultati ad un pubblico sempre più ampio.
5.- I Data Lakes offrono una visione più rapida
Questa ultima differenza è il risultato delle quattro anteriori. I Data Lakes contengono ogni tipo di dati. Permettono all’utente di accedervi prima che vengano trasformati e strutturati. E generano report più rapidi rispetto all’utilizzo del Data Warehouse.
Ovviamente, questo accesso ha un prezzo. Il lavoro solitamente realizzato dal team di sviluppo del Data Warehouse non può basarsi su tutte le fonti di dati per effettuare le analisi. Ciò lascia agli utenti la responsabilità dell’esplorazione. Possono usare i dati come meglio credono. Ovviamente il primo livello di utenti menzionato magari non vuole esplorare ma semplicemente ottenere un report con KPIs concreti e predefiniti.
Nel Data Lake, questi utenti faranno uso di viste più strutturate di dati, qualcosa simile al Data Warehouse. La differenza è che questi punti di vista esistono come metadati. E sono situati al di sopra del Data Lake, al posto delle tabelle strutturate che devono essere gestite da uno sviluppatore.
Come scegliere tra le opzioni di Data Lake per processare i dati?

La cosa migliore in questi casi è considerare i benefici che possono fornirti:
- Una semplice scalabilità di fronte a grandi volumi di dati.
- L’immagazzinamento è più economico.
- Analisi più agili.
Non tutti i servizi del Data Lake sono uguali. E anche se la maggior parte di essi ha funzioni di importazione automatizzate, immagazzinamento dei dati scalabili o interfacce semplificate per l’amministrazione, la proposta finale cambia in funzione del fornitore. Per scegliere è importante verificare la configurazione di sicurezza e l’integrazione.
La creazione di un data lake di proprietà è un’altra opzione da considerare. È l’opzione scelta da molte aziende per processare i dati cloud. Nonostante per ciò che riguarda la sicurezza ci siano vantaggi, per trasformare questo obiettivo in realtà bisogna contare su professionisti specializzati.
Le strategie di Data Lake possono essere particolarmente opportune se la tua azienda mette in pratica piani di marketing basati sul Email Marketing e Marketing Automation.
In questo modo potrai creare un sistema per raccogliere informazioni da tutti i canali e utilizzarli per a seconda delle necessità aziendali. Prova i sistemi di Email Marketing e Marketing Automation di MDirector e scopri i benefici dell’immagazzinare i dati degli utenti per la tua azienda.

















