¿Qué es un Data Lake?
el 09 de junio de 2017
el 09/06/2017
Probablemente lo hayas escuchado en más de una ocasión y te lo estés preguntando. ¿Qué es un Data Lake? Aunque si tu organización no es madura en Business Intelligence, lo más seguro es que todavía no hayas vivido los problemas que ese estado causa. Y, como consecuencia, no has tenido por qué acercarte al concepto de Data Lake.
Como puedes imaginar, uno de los mayores desafíos a los que una empresa se enfrenta se encuentra en el crecimiento de datos. En la era digital en la que estamos inmersos la información está por todas partes. Y se multiplica a la velocidad de la luz.
Y todos los datos pueden resultar muy valiosos. En otras palabras: no hay que dejarlos pasar. Y es aquí donde entra en juego cierto punto de organización y de gestión para saber cómo ordenar todo este conocimiento.
ÍNDICE DE CONTENIDOS
¿Quieres saber qué es un Data Lake?
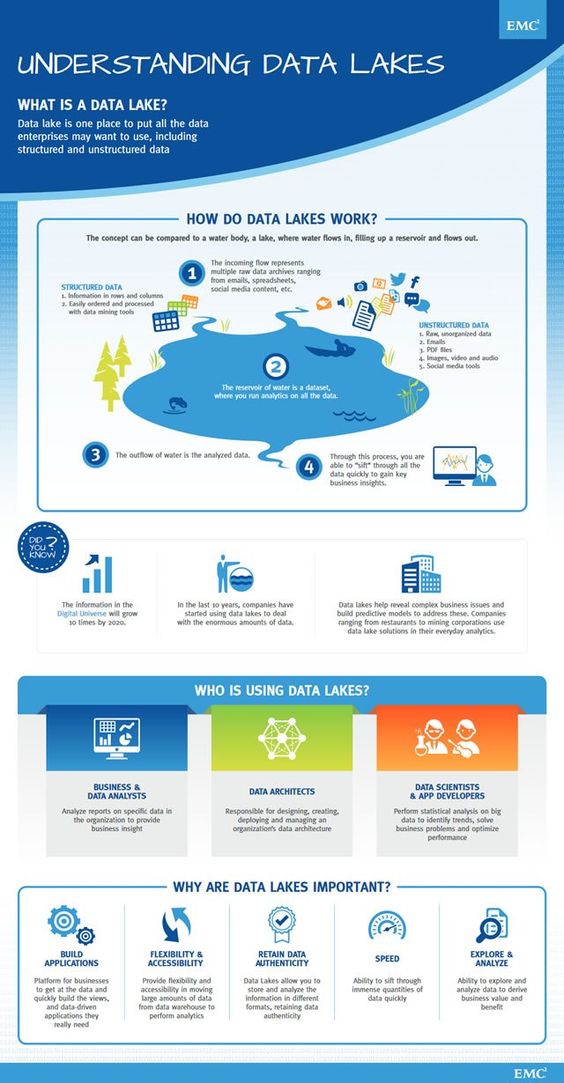
Probablemente ya hayas relacionado este concepto con el Big Data. Un Data Lake es un repositorio en el que se almacenan todos los datos de la empresa. Independientemente de que estén estructurados o no, todos estos se encuentran en bruto, sin ninguna organización, para analizarlos posteriormente.
[bannerHero]De hecho, las empresas vierten los datos y los recuperan cuando quieren. Únicamente en ese momento se procede a ordenarlos y a diseñar una estructura que haga más fácil su posterior análisis.
- Diseñar una política pública.
- Crear una estrategia de marketing.
- Predecir la evolución de una enfermedad en la población.
¿Cómo se puede hacer? Ponte en situación. Si tienes los historiales médicos de los pacientes de un centro, resultará más sencillo detectar un patrón de contagio de una enfermedad o los momentos en los que se dan los brotes.
¿Te preguntas cómo afectaría al marketing? Muy fácil, si una tienda de ropa, por ejemplo, detecta las preferencias de sus consumidores, sabrá cuáles son sus productos preferidos o cuándo se viven bajas en las compras. A partir de ahí resultará mucho más sencillo determinar los momentos clave para lanzar promociones.
¿Qué diferencias existen entre un Data Lake y un Data Warehouse?

Hacer una comparación entre un Data Lake y un Data Warehouse es una de las mejores maneras de entender cómo están evolucionando los sistemas de almacenamiento de datos. Tal y como puedes ver en la infografía de DataFloq cada sistema tiene sus pros y sus contras.
1.- Un Data Lake conserva todos los datos
Durante el desarrollo de un almacén de datos se gasta una cantidad considerable de tiempo analizando las fuentes, entendiendo los procesos de negocio y perfilando los datos. Como resultado, se obtiene un modelo de datos altamente estructurado que ya está listo para la generación de informes.
Una gran parte de este proceso incluye también un procedimiento de toma de decisiones. Qué datos se incluyen y cuáles no. Por lo general, si los datos no se utilizan para responder a preguntas específicas o no son imprescindibles en algunos informes pueden excluirse. De esta manera, se simplifica el modelo y se conserva el espacio.
Sin embargo, un Data Lake conserva todos los datos. No solo los que son vitales en ese preciso momento sino todos aquellos que están guardados que pueden hacer falta en algún momento. Lo que proporciona varios beneficios sobre todo en cuanto a la parte de análisis.
Este enfoque es posible porque el hardware para un Data Lake suele ser muy diferente del que se utiliza para un almacenamiento de datos corriente. La comodidad, los servidores que hay disponibles y el almacenamiento más barato suponen una ampliación de un Data Lake a terabytes y petabytes bastante económico.
2.- Un Data Lake soporta todo tipo de datos
Los almacenes de datos generalmente consisten en información extraída de sistemas transaccionales. Y, por lo tanto, incluyen métricas cuantitativas así como otros atributos que los describen.
Las fuentes de datos no tradicionales como pueden ser los registros del servidor web, los datos de los sensores, la actividad de una determinada red social, imágenes o los textos suelen ignorarse. Y aunque se siguen encontrando nuevos usos para este tipo de datos, consumirlos y almacenarlos supone un costo elevado y resulta bastante complicado.
Para que sepas bien qué es un Data Lake debes tener clara la idea de que este concepto abarca todo tipo de datos no tradicionales. Es decir, se guarda todo sin tener en cuenta su estructura o su fuente. Se mantiene la información en bruto y solo se transforma en el momento en el que sea necesario.
Este enfoque se conoce como «Schema on Read» en comparación con el enfoque «Schema on Write» utilizado en el Data Warehouse.
3.- El Data Lake apoya a todos los tipos de usuarios
En la mayoría de organizaciones, más del 80% de los usuarios son operacionales. Es decir, quieren obtener sus informes, ver sus métricas claves de rendimiento o trabajar sobre el mismo conjunto de datos en una hoja de cálculo diariamente. Y para ellos, el Data Warehouse es ideal. Ofrece una estructura clara, fácil de usar, de comprender y, sobre todo, está diseñado para responder preguntas.
Un 10%, en cambio, hace un análisis mayor sobre esos datos. Es decir, estos usuarios utilizan el Data Warehouse como una fuente más. Sin embargo, a menudo vuelven a los sistemas de origen para obtener datos que no están incluidos en el almacén. E, incluso, incorporan nuevos datos de fuera de la empresa.
Por último, el 10% restante hace un análisis profundo. Estos usuarios saben qué es un Data Lake y crean fuentes de datos totalmente nuevas basadas en la investigación. De hecho, estudian muchos tipos diferentes de datos hasta llegar a nuevas preguntas que intentan dar respuesta a sus necesidades.
Aunque pueden usar el Data Warehouse prefieren ignorarlo. Ya que, a menudo, su utilización supone tener un conocimiento que no disponen. Sin embargo, cuentan con ciencias de datos y utilizan herramientas de analítica avanzada.
El enfoque del Data Lake apoya de la misma manera a todos estos usuarios. La ciencia de datos «ir al lago» y trabajar con toda la información en bruto que necesiten. Mientras tanto, los otros usuarios harán uso de vistas más estructuradas de los datos proporcionados para uso.
[bannerHero]4.- Los Data Lakes se adaptan fácilmente a los cambios
Una de los principales desventajas de los Data Warehouse es que se tarda mucho tiempo en cambiarlos. Ten en cuenta que durante el desarrollo de la estructura del almacén se gasta un tiempo considerable. Sin embargo, aunque un buen diseño de este «almacén» pueda adaptarse al cambio, el proceso de carga de datos es tan complejo que estos cambios necesariamente consumirán algunos recursos para desarrolladores. Que, cómo no, conllevarán tiempo.
Como puedes imaginar hay muchas cuestiones comerciales que deben abarcarse. Y esto no puede esperar a que el equipo de almacén de datos adapte su sistema. Actualmente el usuario quiere respuestas aquí y ahora. Y, por eso mismo, se han creado muchos sistemas de auto-servicio de inteligencia empresarial. Sistemas que auto responden para ahorrar tiempo y resultar más eficaces.
Para entender qué es un Data Lake, en cambio, debes tener clara una idea: Son los usuarios quienes tienen el poder de ir más allá de la propia estructura de ese «almacén«. Teniendo en cuenta que todos los datos se almacenan en bruto y siempre están accesibles, esta práctica es posible.
Se demuestra que el resultado de una exploración ha resultado útil y se quiere volver a repetir, puede aplicarse un esquema más formal. De hecho, ahí es donde se podrían desarrollar sistemas de automatización y reutilización para extender los resultados a públicos más amplios.
5.- Los Data Lakes proporcionan una visión más rápida
Esta última diferencia es el resultado de las cuatro anteriores. Los Data Lakes contienen todo tipo de datos. Permiten a los usuarios acceder a ellos antes de transformarse y estructurarse. Y pueden llegar a sus resultados más rápido que utilizando el Data Warehouse.
Sin embargo, este acceso también tiene un precio. El trabajo típicamente realizado por el equipo de desarrollo de Data Warehouse no puede hacer uso de algunas fuentes de datos para realizar un análisis. Y esto deja a los usuarios como responsables de la exploración. Pueden usar los datos como mejor les parezca. Sin embargo, el primer nivel de usuarios mencionado anteriormente tal vez no quiera hacer esto. Quizás le interese simplemente obtener un informe con unos KPI’s concretos y predefinidos.
En el Data Lake, estos usuarios de informes harán uso de vistas más estructuradas de los datos, algo más parecido al Data Warehouse. La diferencia es que estos puntos de vista existen principalmente como metadatos. Y se sitúan sobre los Data Lake, en lugar de tablas físicamente estructuradas que requieren de la ayuda de un desarrollador para ser modificadas.
¿Cómo elegir entre las opciones de Data Lake para el procesamiento de datos?


















